In my life playing around with design, I’ve often stumbled upon the challenge of designing systems: having to imagine or transform gnarly entanglements which often feel too large and too complex to actually accomplish anything meaningful without dedicating years of your life to being absorbed by a very specific problem. Education interventions are a great example of this: everyone involved with them has been working on the same or similar problems for years and speak from a place of expertise, often to highlight how many of the new things you can imagine can’t get done.
When faced with the design of systems, there are many things that can go wrong: from dedicating years to designing a complex solution that only addresses imaginary problems, to releasing something in the wild that ends up doing more harm than good — something that can happen often too easily when approaching the design of systems superficially. The best tool in your kit when confronting a problem if this nature is experimentation: as usual, by releasing things in bits and pieces and learning from small, local interactions, you can gather a lot of data to inform iteration and deployment at scale. But systems are weird. You can’t really experiment with them all at once, and sometimes experimenting with them introduces new constraints and challenges that are hard to get around (regulation, ethics, feasibility, budget, etc.).

Experimentation can help ensure systems don't have large-scale unintended consequences. Like any zombie movie.
I do believe, however, you can experiment with systems, you just need to be rather careful and intentional about it. I’ve tried to capture what are, in my experiences, some creative ways to go about leveraging experimentation at the service of informing the design of new systems (or the transformation of old ones) that I hope can be helpful to others who might find themselves asking similar questions. But most of all, I’d love to hear some feedback from people who might have tried any of these and might have gathered interesting learnings, or from people who might have tried entirely different approaches that might have been successful (or otherwise).
I don’t mean to imply design can solve all problems — sometimes it can do a lot more harm than good, for sure. But I certainly think when you’re more aware of the constraints to what design can do, and how to interface it more effectively with other disciplines, it can bring about interesting new ways of looking at existing problems. Sometimes, when we’re observing the breakdown of rather large societal systems as we’re observing today, new ways of looking at existing problems are certainly valuable and necessary.
What’s a System, Anyway?
What are these gnarly entanglements I keep talking about? My own general understanding of systems comes from Austrian biologist Ludwig Von Bertalanffy’s general systems theory, from which I inherit a number of concepts without going too deep into the technicalities: a system is a collection of interconnected, interdependent elements with multiple non-linear inputs and outputs between them. Systems are complex: the interactions between their elements can often be non-obvious, and the system as a whole often exhibits various forms of epiphenomena — properties that correspond to the system as a whole but not to its constituent elements, or emergent properties. Sometimes, when designing systems, we’re actually looking to create or capture those emergent properties: think about the design of a nuclear reactor, for example, where heat and power are the output of a carefully-calibrated system.
The nuclear reactor is also a great example because systems, due to their complexity, can be hard to grasp and understand at plain sight. Our human brains are not great at processing information at the exponential level, but the entanglements of systems often mean (1) there will be unintended consequences we couldn’t have predicted, and (2) those unintended consequences might manifest themselves very suddenly, very quickly, and in rather large proportions. A nuclear reactor running amok — think Chernobyl — can get out of hand very quickly in ways its designers might not have anticipated.
Systems are so great at moving information around, that if the wrong information suddenly becomes accepted by the system, bad things can happen. But if the right information makes it through, great things can happen as well.
This video is one of my favourite illustrations of how systems operate.
Perfectly Balanced Systems Don’t Exist
Another important thing to remember about systems is that they often exceed our capacity to control them — there are way too many elements, stakeholders, or nodes in the network for all of them to be perfectly aligned at the same time. On top of that, systems exist within larger systems. Organisms exist within ecosystems which exist within the planet which exists within the Solar System and so on. Because of these interactions, all sorts of systems, whether natural, social, or otherwise, are often receiving a lot of information from their surrounding environment and responding to it.
In short, systems evolved and adapt. Only systems in perfect isolation could be conceived of being in a perfect balance — but such perfect isolation is only theoretical. Real systems in real conditions, like education systems and markets and healthcare systems and so on, are operating in continuous feedback loops with the rest of the world. The design of systems cannot possibly imagine them to be fixed in time. You have to allow and design for certain degree of variability, of serendipity, if you don’t want the system to break. That’s really hard: you have to think about designing something that works even in the presence of unpredictable things that might be trying to make it not work.
Do No Harm (And Other Ethical Considerations)
Because of some of these properties, the design of systems and the experimentation with systems needs to be mindful of ethical considerations at an even larger degree than your standard approach to design. The reason is unintended consequences: systems are just so much more likely to exhibit them in ways that can be rather tragic. Experimenting with systems, then, means that you’re playing around with the colourful wires of a bomb detonator. A questionable idea, but it can be done provided you take the right precautions.
Similarly, experimenting with systems means you should be asking about what could go wrong early and often. And really probe for that question as much as you can. What is literally the worst thing we can imagine happening? And have we been thorough enough to confidently say we’ve mitigated against that? Murphy’s Law immediately comes to mind — “anything that can go wrong, will go wrong, at the worst possible time” — and it becomes especially relevant given its original context: Murphy’s Law came about as a security mantra for flight test pilots experimenting with new technology in the 1940s and 1950s. The general idea being, if you assume Murphy’s Law to be correct, what else do you need to consider to minimise the probability of error or accident?
There’s no way to demonstrably claim you’ve brought it down to zero. But it’s important to always make sure you’re trying your very best to do so.
The Dangers of Synchronised Swimming
The flip side to all that is the risk of trying too long and too hard to get the system design just right. Because perfectly balanced systems exist only in theory, and because some share of unintended consequences in complex system will always remain hidden from view, it’s easy to fall into a trap where you end up refining the design of a system ad infinitum. Without a forcing function, you can easily fall into a logical frame problem: there will always be new data available to continue refining a design, therefore refinement of the design will continue as long as there is new data available.
In other words, you never actually ship anything or change anything, but remain stuck in an endless design loop. Even worse, you might end up spending a lot of time fixing imaginary problems: resolving internal inconsistencia and polishing details endlessly, that when actually confronted with reality nobody actually cares much about or didn’t actually matter as much as you thought they would. This is why experiment with systems is important: you need to get actual, real data from actual, real interactions in order to inform what problems are more important than others, and make sure you’re solving for those first. Since systems will always experience a need for evolution, and that evolution is a consequence of the interaction with the world, you need to observe the system actually operating in the world to better understand how to shape and frame that evolution.
And, of course, if the system you’re designing has as its ultimate goal some form of social impact of business performance (business models are systems, too), that desired output will not actually become realised until the system is in operation. So you have to figure out some way of testing for value and getting real data from real interactions, while balancing out the complexity of the entanglements and the risk of creating harm.
That’s where experimentation comes in. And I’ve been able to come up, based on experience, with four different approaches towards experimenting with systems.
Approach 1: Creating Sacrificial Artefacts
The simplest way of experimenting with a system is to draw it out. Almost sounds boring, but it’s actually very important. Visualisations can be incredibly helpful to understand the way information and interactions flow between elements. They can help you identify and address the most obvious problems and make complexity slightly more tangible.
Stakeholder maps, user journeys, and sacrificial concepts are helpful tools to get some early reactions from multiple stakeholders. It doesn’t really matter if you have the right design — it’s actually better if you don’t. Come up with as many wrong or potentially-wrong versions of your system as you can and put them in front of a variety of stakeholders, and just listen to them telling you about all the ways in which you’re wrong. This is extremely valuable data. It’s also especially helpful to map out the potential consequences of getting the solution wrong and to begin hedging against those risks.
Be mindful, though, of making sure you’re testing for the system and whether the system is achieving the desired outcomes, as opposed to testing for its elements and their expected output. In the pursuit of understanding complex problems, it becomes very easy to get stuck solving complicated problems and derive the illusion we’re making progress towards the larger mission when we’re actually not.
Approach 2: Setting up a Boxed Universe

Rick's car is powered by a miniverse contained within the battery shell.
(This one is inspired by Rick and Morty’s The Ricks Must Be Crazy episode in season two.)
Sacrificial artefacts can get you very interesting data, but they’re still not giving you a sense for what a system looks like when it is operating. Working to set up a boxed universe can help you with that: iterative design works because tight feedback loops are possible at a very low cost, enabling you to try things before committing to long design cycles. This is why it’s so much easier to iterate mobile apps (you can push an update to thousands of people almost instantly) than it is to iterate a bridge (because building a bridge takes a lot of time and costs a lot of money) or research on a new drug (where the consequences for getting it right can be catastrophic).
It’s worth asking whether you can shorten the feedback loops for whatever system you’re designing by unlocking some of your variables and focusing on what you can learn quickly that is relevant for future design. Feedback loops in education, for example, can be hard to get around: when is an education journey narrative-complete — when can we measure whether the education system did its job effectively? Is is after every school year? After graduation? A year after? When the students get their first jobs? Ten years after? It’s really hard to say, and it’s really hard to measure. And impossible to agree on.
What self-contained version of your system that is narrative-complete (it does what it’s expected to do relatively well) can you scramble together in a month, or in a week? What’s the smallest self-contained experiment you can run where you’re taking all of the pieces together for a quick spin and then pulling the plug? You’re essentially looking for information on how the pieces of your system work (or fail to work) together: what information flows exist, and which ones don’t exist that are necessary. What needed to be improvised on the fly that should be designed for, and what was designed that ended up being irrelevant. Boxed universe experiments are useful to test for internal consistency and make sure you’re focusing on solving the right problems when you iterate on them — they help you make sure you’re building a universe that won’t fall apart two days later, like Philip K. Dick would say.
Approach 3: Setting up an Experimentation Sandbox

Sandboxes provide safe environments for play and experimentation that can be monitored much more closely.
In software development, there’s the well-established practice of having multiple environments: at the very least you’ll have two, a development environment where you’re trying out new things, and a production environment optimised for stability and continuity. The logic is obvious: you don’t want your testing and experimentation to compromise your users’ capacity to get relevant stuff done.
The same logic can be applied to thinking about how to experiment with your system. What conditions can you replicate at a small scale in order to set up an experimentation sandbox? An environment where experimentation can be carefully monitored to make sure things aren’t getting out of control, but you can still try new things, make changes on the fly, and observe the results you get.
Your experimentation sandbox can be physical — take one store from the entire store network, or one medical center out of the entire healthcare system, or only within one neighbourhood, and so on — or it can be logical — experiment only with a sample of users, or during specific times of day, or with one specific set of inputs. The parameters for your sandbox will be contingent on the nature of the problem you’re working with and what you need to learn. But based on those parameters you can make sure you have the right monitoring in place: not just measuring for the right outputs, but monitoring the right throughputs. Once you have sandbox in place, you should think about how you start monitoring even the things you don’t expect might go wrong, just so you can be better prepared if something goes wrong or just behaves unexpectedly.
Having access to a sandbox shouldn’t mean, however, that within the sandbox anything goes: there’s are multiple points of view with very legitimate criticism as to how sandboxes can be abused, or can create perverse incentives to experiment with disregard for the wellbeing of individuals and communities affected by the very sandbox. Concerns about informed consent and the need for transparency, supervision, and regulation are not waived by having a sandbox: to the contraty, a sandbox should exist to make it easier for all these things to happen in tight coordination loops with responsible stakeholders. Sandboxes are not get-out-of-jail-free cards.
Another thing to be mindful of is that the staffing and operation of a sandbox environment is different from a production environment: in production, you expect things to have been thoroughly tested and documented, and many protocols and processes are most likely already in place to make scalability possible. Testing, documentation, protocols, and processes are useful to either limit, constrain or orient local decision-making: how do we support people in the front lines of the system to make good decisions with the limited information they’ll have? These conditions are not true in the sandbox. Since we don’t know what we don’t know, the people operating the sandbox need to be highly capable of exercising local decision-making on the fly. Their learnings will later inform the protocols and processes you’ll need to get to scale.
Approach 4: The Strangler Approach
When building software systems to replace existing systems serving a critical function, a lot of attention needs to be paid to make sure you can pull off a successful migration. If you’re replacing the software managing medical histories, for example, you must be very sure your new system will have all the relevant data it needs when it needs it so that the right medical decisions are made at the right time by the right people. You need to balance both continuity and innovation at the same time — two things that, by their very nature, are not in balance.
The Strangler Pattern is a clever way to do this that I’m borrowing from software engineering to suggest it can find applications in multiple context. In essence:
The Strangler Pattern is a popular design pattern to incrementally transform your monolithic application into microservices by replacing a particular functionality with a new service. Once the new functionality is ready, the old component is strangled, the new service is put into use, and the old component is decommissioned altogether. Any new development is done as part of the new service and not part of the Monolith. This allows you to achieve high-quality code for the greenfield development.
In other words, you’re building the new system roughly as a parasite of the old system. As elements of the new system are built out and tested to satisfaction, these new elements start taking over specific inputs from the system and feeding back the outputs to the right place in the old system — working effectively as a by-pass to the old element. You get any additional value from the new element right away, without compromising (hopefully) the integrity nor the continuity of the system as a whole. This enables you to ship value from your new system design a lot faster, observing how pieces being to operate in a production environment, and mitigating the risk of switching entirely to a new system and watching everything burst into flames overnight.
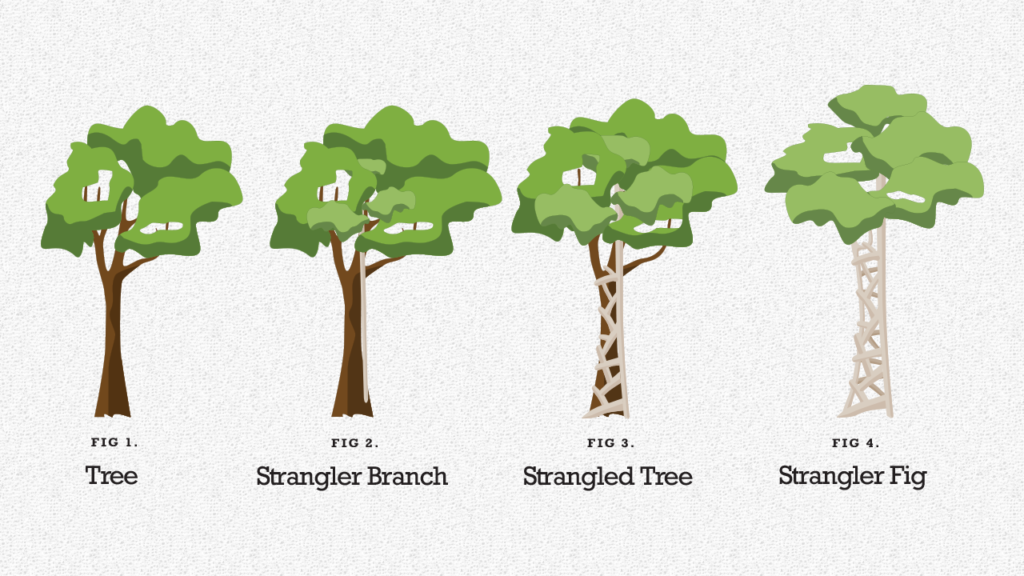
The Strangler Pattern is inspired by the growth patterns of the Strangler fig.
There’s an additional layer of value here: if you design your system to be compatible with a Strangler Pattern to accelerate/facilitate migration, you’re also effectively embracing architectural changes to will facilitate future evolution of the system:
There’s another important idea here - when designing a new application you should design it in such a way as to make it easier for it to be strangled in the future. Let’s face it, all we are doing is writing tomorrow’s legacy software today. By making it easy to add a strangler fig in the future, you are enabling the graceful fading away of today’s work.
I’m going to explicitly sidestep the discussion about whether microservices are a great idea or a terrible hoax in the world of software development, and I’m going to stick the analogous potential. If you design your system as a collection of loosely-coupled elements as opposed to one tightly-couple monolith (where things cannot be iterated or updated without affecting the operation of all other elements), you’re setting things up for a world of pain in the future. Remember, systems forcibly evolve very organically: if evolution is factored into the design, then the system can adapt much more quickly and effectively to changes in reality. And as the last few weeks should have demonstrated to anyone, changes in reality will happen with much greater force than you could have anticipated.
Which to me implies it’s actually a rather good idea to design your system around small bits that can be tested together and deployed separately over time, rather than needing all of them to be turned on at the same time.
But I Must Be Missing Many Things
These are just a handful of considerations and approaches I’ve ever tried or considered when working with the design of systems. The more I think through them, though, the more I also realise they’re not even at odds with each other. They can be rather complementary depending on what stage you are in your design journey. Sacrificial artefacts can be very helpful when starting out, but boxed universes are great at getting you more textured data on internal consistency when you’re still thinking about the layout of your system as a whole.
Sandbox environments, on the other hand, are helpful as you move into more nuanced stages in design and need to actually think through what the pieces look like and how they will operate. And as the design of all these pieces is delivered, a strangler pattern can help you move some of these things into production without having to wait for the others — assuming you’ve made the right architectural choices from the beginning.
I know this walkthrough has been rather abstract, but then again, so are systems. I’ve borrowed very loosely from software engineering patterns because I think they’re very illustrative, but I’m of the belief these patterns can be applied to a variety of problems when designing systems. Business models, markets, education models, healthcare systems, and many other categories can benefit from design, and they can certainly benefit from experimentation to ensure the right choices are being made through the design process and beyond. These are somewhat living, organic entities, prone to veering off into unpredictable states. So the more we can balance creativity and experimentation with responsibility and safety, the more we can make sure these systems are optimised for the right things, and are having a positive impact on the communities affected by them.
Still, I’m far from an expert on this. And I would love to know more about other things people have tried, or pointers as to the nuance of any of these techniques or others. What have you tried that has worked or failed? What have you struggled with when it comes to experimenting with complex systems? Drop me a line or a tweet and I’ll really appreciate it!
