About the Project
Date:
October 2012
Location:
Cambridge, MA
Team:
Rodrigo Davies
Alex Gonçalves
Eduardo Marisca
Lingyuxiu Zhong
Sourcerer is a browser extension that helps journalists and readers to understand and interpret scientific reports. It is based on a simple set of metrics that highlight key information about studies and provides a means for readers to explore other relevant information on their topic, drug, or company of interest. Sourcerer is compatible with Google Chrome and is currently functional in a proof-of-concept form. This project was assembled for MIT’s CMS.950 graduate class, Workshop in Comparative Media, by Alex Gonçalves, Eduardo Marisca, Lingyuxiu Zhong and Rodrigo Davies.
Initial Design
We first became interested in the community of scientific journalists as a result of Alex Goncalves’ personal experience working in the field. Our initial hypothesis was that this community of writers is facing a three-sided literacy deficit with respect to the interpretation of scientific research: material, cognitive and social. The hypothesis was based on observations about the material, institutional and education limitations faced by science journalists. Most newspapers and mainstream media outlets have limited and decreasing budgets, which means that science journalists work with a wide range of topics and their level of specialization is highly variable. With the exception of a few professional graduate programs dedicated to teaching the combined skills of journalism and scientific research, for which the Science Writing at MIT is an example, very few institutions offer formal training courses for science writers. As a result, scientist writers are ill-equipped to understand the limitations of complex research and, given the additional time and budget restrictions impacting their investigation process, are prone to misrepresenting scientific reports to the public. These observations are supported by the rising popularity of journalists such as The Guardian’s Ben Goldacre, whose Bad Science series consistently highlights many of the literacy issues we decided to focus on. A further and well-acknowledged complication is the unreliability of many scientific studies themselves, as a result of organized corporate influence, particularly from the pharmaceutical companies whose products are being examined. Even a science writer aware of the appropriate metrics to analyse a scientific report may be unaware of these external factors affecting reliability. With this hypothesis in mind, we believed that we could advance science journalists’ literacy towards scientific studies through a mixture of two types of support.
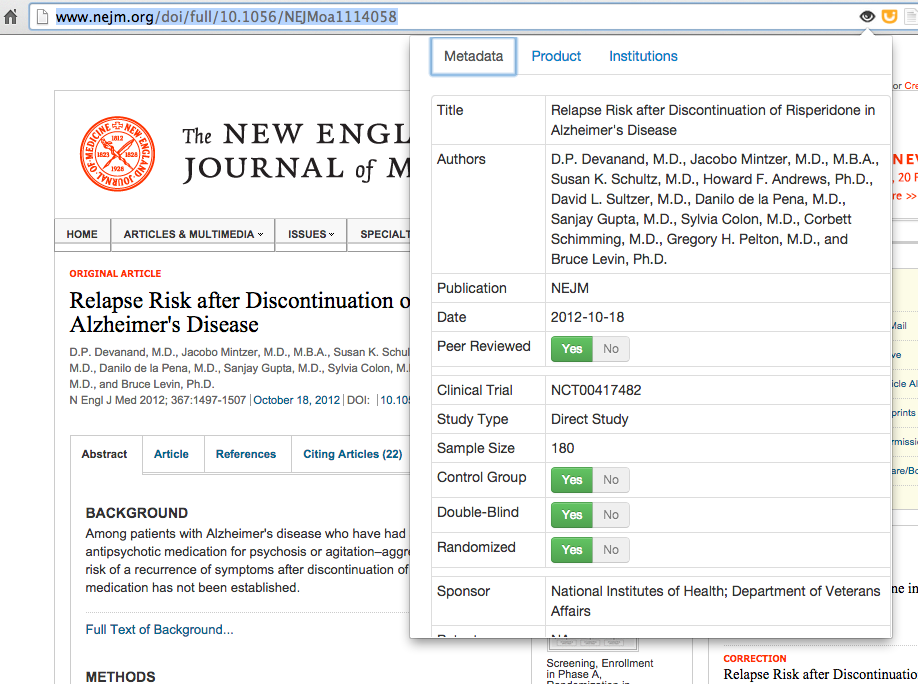
Material: a simple system of string and boolean metrics to analyse reports, such as sample size, randomized (T/F) and control group (T/F).
Social: a forum and website that allows the user to vote articles up and down, using the open source framework of Reddit, and a forum open to registered members for the discussion of articles.
Focus group and iterative process
Our user research consisted of an interview with a scientist who coordinates the Brazilian branch of the Cochrane Collaboration (a prominent foundation dedicated to publishing analyses of the effectiveness of scientific studies) and a focus group of students at the Graduate Program in Science Writing at MIT. Our focus group participants said that science journalists face the following constraints and literacy issues:
- They spend a lot of time analysing reports that they later discover to be unsound
- They find it hard to judge the validity of information in reports
- They are not always able to identify the funding source behind a particular report
- Press releases associated with scientific reports tend to overhype the content of the reports
They said that they face difficulties researching topics related to the pharmaceutical industry given the funding and influence questions involved. However, when asked how they deal with a field full of conflicts of interest, they only rely on previous experience. Within what they described as the ‘tight-knit’ community of science journalists, they feel that poor reporting by other journalists, using faulty research, reflects badly on the whole community. They perceive a need for science journalists to win the public’s trust, since they feel the public are by default skeptical of scientific research in the U.S. (new scientific findings are usually perceived as disproof of earlier findings instead of as progress), and subsequently of science reporting. Our focus group of science journalists suggested that the following information would be helpful in analysing the veracity of reports:
- Metadata on the sample size
- Information on previous work by the same author and institution
- Markups and comments on reports by trusted scientists
The group also made the following remarks which are likely constrain the functions of our platform:
- Science journalists are unlikely to discuss reports with their peers prior to publication (due to embargo rules and competition between publications / media outlets)
- Many journalists are reluctant to call out other journalists' mistakes publicly for fear of facing similar reprimand themselves in the future
Design iteration and implementation
Following our user research and further discussion, we decided to adjust and more narrowly focus the literacies we were seeking to address. Given the science writers’ observation that our prospective users were unlikely to communicate with each other ahead of publishing their articles, we decided to remove the social literacy support. We also wanted to address the need for cognitive literacy support, prompting science writers to think critically about the potential unseen influences on a scientific report. We felt this could best be addressed by providing related news stories and links covering the topic, product and companies featured in a given article. We divided this information into three groups: the Metadata (broadly following the model described above), Product information and Institutional information. Since we were able to secure the cooperation of the Cochrane Foundation, we decided to include any relevant studies conducted by their research teams under the Product tab. Given that our final design was more focused on the science writer as an individual, we felt that this user group would be best addressed by a web browser extension that would accompany a science writer’s normal research procedures, rather than the social website we had originally envisaged.
Project Execution
Our first prototype was premised on the idea that we would construct a dynamic database and build a working platform. In our final design phase we took the decision to construct the platform as a proof of concept rather than a working platform, since the challenges of parsing and processing many thousands of scientific studies was deemed impractical for the group to address within our working time-frame.
Data entry and database building: Alex selected 12 articles from 4 prestigious scientific articles in the field, and the team jointly coded the articles according to the metrics we defined. Ling wrote these codings into 12 static web pages, collaboratively designed using the Twitter Bootstrap framework.
Browser extension design: Eduardo used javascript to develop the wrapper for the browser extension, including the filtering process to allow the browser to detect when a user visits one of the 12 article URLs included in our sample set.
Web front-end interface design: Rodrigo designed a simple web interface to introduce the Frontend interface design and provide instructions and a download mechanism for the browser extension.