Este fin de semana largo he tenido tiempo para seguir avanzando el trabajo que empecé hace tiempo con la digitalización del Informe Final de la Comisión de la Verdad y la Reconciliación . Soy de la idea de que un documento de tal magnitud como el IF tiene que tener una representación digital que facilite su análisis, su procesamiento, su difusión y, sobre todo, su discusión. Pero a pesar de que se presentó hace apenas trece años, el IF no cuenta con una buena versión digital o interactiva: fue pensado, preparado y finalmente publicado bajo la lógica del documento impreso.
He podido avanzar más con el trabajo alrededor de las Conclusiones del IF — 171 pequeños pedazos de texto que buscan sintetizar dos décadas de violencia política en el Perú, sus causas y sus secuelas. Son quizás la parte más leída y difundida del IF. Y por lo mismo, desde hace tiempo quiero construir una versión nativa digital de este contenido. Lo que he podido implementar ahora es una aplicación completa (aunque aún muy básica) alrededor de las Conclusiones — en realidad, dos aplicaciones: una API que permite acceder a las Conclusiones almacenadas en una base de datos, y una versión web que se alimenta de esa API para presentar el texto a los usuarios.
Estas dos aplicaciones pueden servir como herramientas de información, de investigación y de consulta. Por un lado, permiten la consulta y el procesamiento del texto como si fuera una base de datos para ser analizada. Por otro, facilitan la creación de herramientas e interfaces que facilitan la presentación de la información, poniéndola en contexto con otras fuentes y facilitando su análisis.
Quiero explicar en un poco más de detalle el proceso de creación de estas herramientas, porque creo que ayuda para ilustrar el tipo de análisis que puede hacerse con este tipo de herramientas.
Preparando la data
En un post anterior expliqué el proceso para convertir la data de las Conclusiones — disponible en la web solo como un PDF con formato — en registros JSON, un formato mucho más fácil de leer por herramientas digitales. En ese caso, lo que hice fue extraer la data, limpiarla, y exportarla en este formato.
Una vez con la data en formato JSON, el siguiente paso fue cargarla en una base de datos nativa a Internet desde la cual pudiera ser consultada. Escogí trabajar con Firebase , una herramienta recientemente adquirida por Google y que ofrece una base de datos muy ligera y flexible donde todos los registros se trabajan nativamente en JSON. Firebase hizo muy simple la carga de datos, y también facilita enormemente la manipulación de los registros directamente en la BD. Puede, sin embargo, ser difícil de asimilar para los que están acostumbrados a BD relacionales basadas en tablas: toda la data en Firebase existe como árboles, cuyos registros anidados se despliegan en ramas.
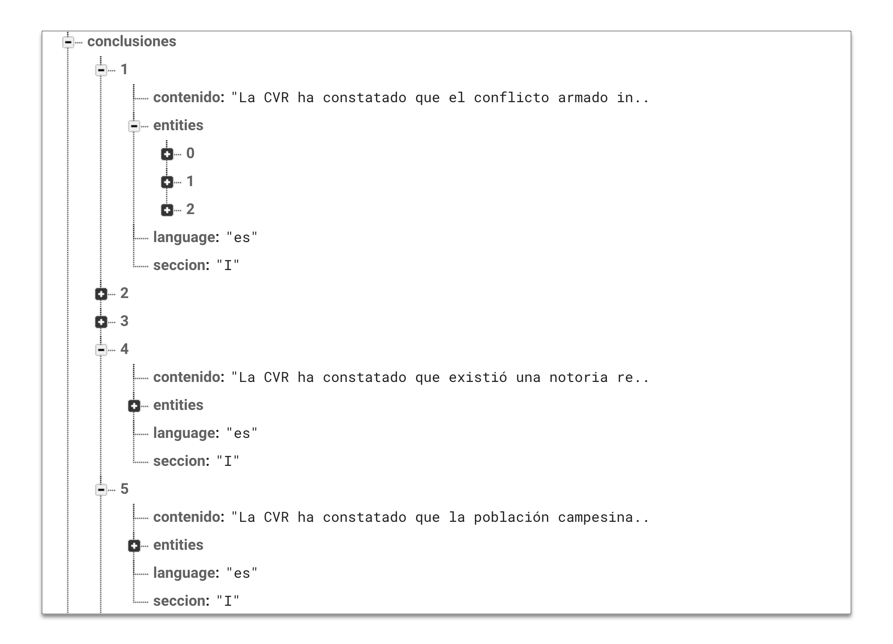
La data estructurada como árboles en Firebase.
Identificando entidades
Hace unas semanas, Google lanzó una nueva API para procesamiento de lenguaje natural que hace disponible su motor de machine learning al público de manera relativamente sencilla. Utilizando esta API, podemos analizar cualquier bloque de texto para hacer reconocimiento de entidades: identificar personas, organizaciones, eventos o lugares que son mencionados en un texto. De esta manera podemos tomar el texto de las Conclusiones y destacar elementos importantes de manera automática — algo que, para un lector neófito, puede facilitar enormemente la lectura pues ayuda brindando contexto al contenido (por ejemplo, identificando que “Alan García” es una persona o que “Ayacucho” es un lugar, y creando un enlace a la referencia correspondiente en Wikipedia).
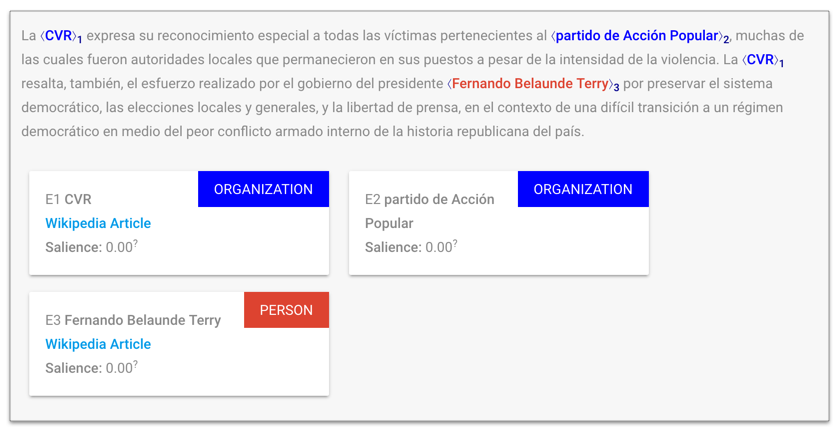
Un ejemplo de análisis y reconocimiento de entidades utilizando la Cloud Natural Language API de Google.
Con esta data podemos complementar muy bien nuestra data existente. Una pequeña aplicación en Javascript nos permite jalar el texto de cada una de las conclusiones, pasarlo a través de la API de lenguaje natural de Google, y recibir de vuelta las entidades identificadas en el texto. La información de las entidades es ahora parte de la BD, ya que es poco probable que cambie y es más eficiente que consultarla continuamente.
Creando nuestra API
El objetivo de crear una API es que sea más fácil para cualquier desarrollador extraer información en un formato estándar, sin tener que preocuparse por cómo conectarse a la BD, cómo está estructurada la data, y demás. Así, cualquier aplicación puede jalar la data fácilmente utilizando pedidos HTTP y recibiendo data de vuelta en JSON. Además, si en el futuro queremos cambiar de BD o la estructura de datos, mientras la nueva herramienta siga respondiendo a las mismas llamadas y devolviendo la misma estructura de datos, todas las aplicaciones que se alimentan de esa API siguen funcionando sin tener que hacer ninguna modificación.
Nuestra API es una aplicación node.js , también muy simple y muy ligera. Esta aplicación, conclusiones-api, abstrae todo el trabajo de conectarse directamente a la BD, y permite extraer dos formas de data: /getconclusiones retorna el contenido para un elemento específico, mientras que /getsecciones retorna un JSON con la estructura maestra de las Conclusiones y las referencias dentro de cada sección (para construir el índice).
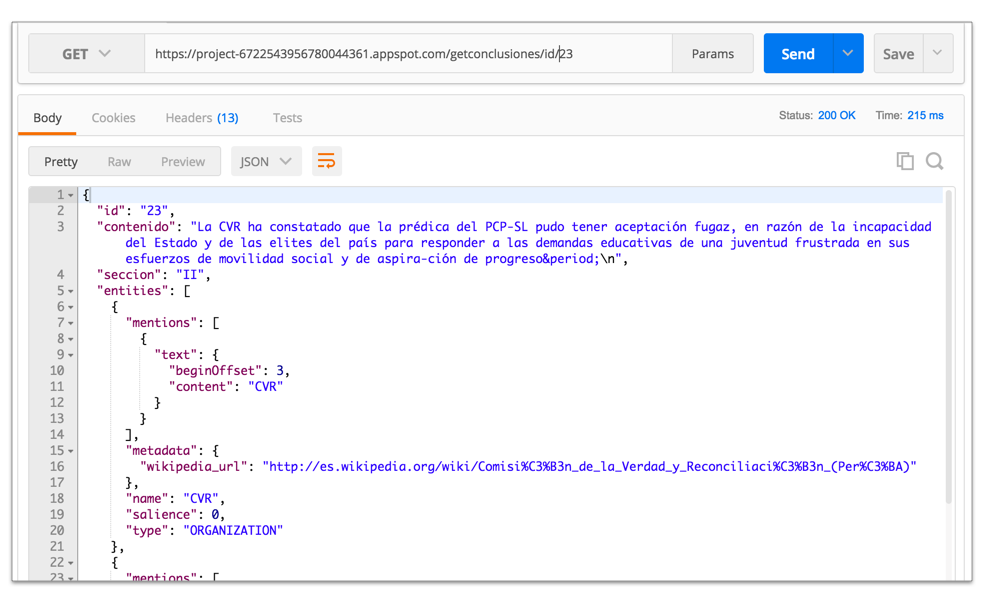
Probando la API utilizando Postman, un cliente para formular HTTP requests.
Cualquier aplicación puede solicitar data a la API — esa apertura es justamente la razón por la que quise abstraer el backend y la data (a través de la API) de la presentación de la data al usuario a través de una aplicación. Aunque todavía no he tenido oportunidad de documentar los endpoints y los retornos para que cualquiera pueda utilizarlos, el procedimiento es bastante sencillo.
Creando la aplicación web
El siguiente paso era crear una manera para que otros seres humanos (ya no otras aplicaciones) puedan acceder a la data. Para eso creé una segunda aplicación, también basada en node.js , que extrae la data a través de la API y la utiliza para crear un sitio web. Esta aplicación, conclusiones-display, no tiene su propia base de datos, sino que jala siempre la versión más actual de la data. Como aún estoy limpiando y mejorando partes del texto, haciendo un solo cambio en la base de datos a nivel del backend automáticamente actualiza lo que se muestra a los usuarios a través de la aplicación web.
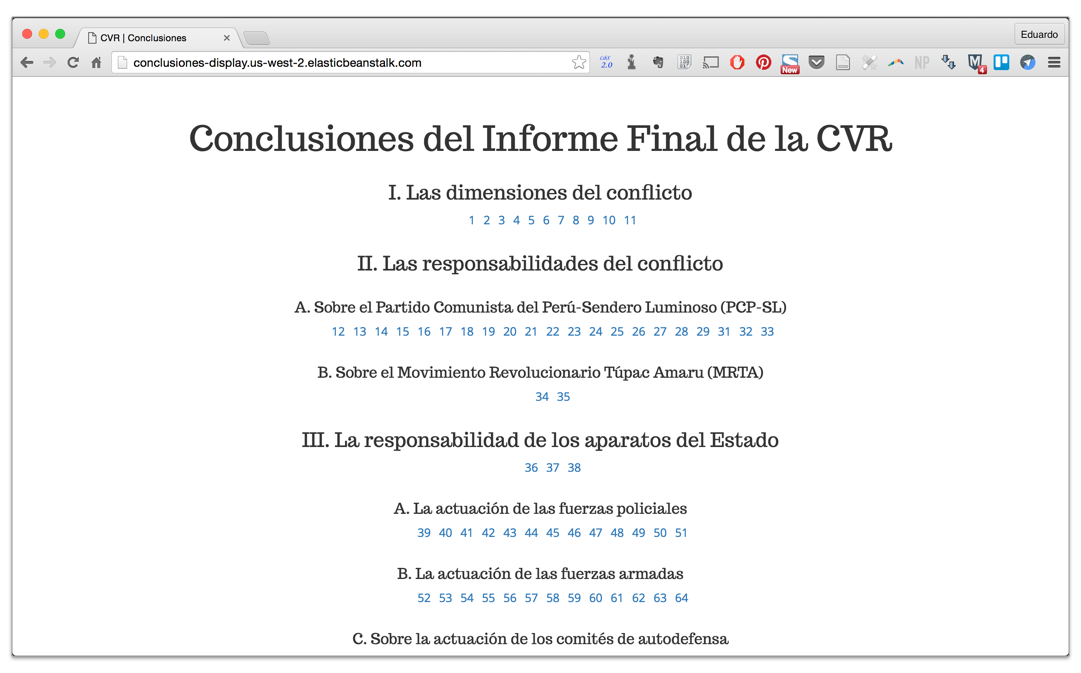
El índice de la aplicación con las referencias a todas las Conclusiones.
La llamada que hace la aplicación web a la API recibe la información de las entidades contenidas en el texto. Una primera versión con todas las Conclusiones ya está disponible . Aún no he terminado de agregar los campos para que se reflejan en la interfaz, pero una vez que hecha la conexión, el texto de cada conclusión vendrá de la mano con las entidades identificadas y los enlaces que aportan contexto a la lectura. De la misma manera, pueden en el futuro agregarse enlaces a artículos, contenido multimedia, y cualquier tipo de información complementaria que ayude a brindar contexto.
Subiéndolo todo a la nube
El paso final de todo este proceso fue hacer que ambas aplicaciones estuvieran disponibles al público. Ambas aplicaciones están disponibles en entornos en la nube — conclusiones-api, el backend, existe como un entorno en la plataforma de Google Cloud , mientras que conclusiones-display, el frontend web, está alojado en la plataforma de Amazon Web Services (por la única razón de que quería aprender a interactuar con ambos entornos). La gran ventaja de esto es que ambos entornos abstraen la necesidad de preocuparse por mantener la infraestructura: en caso de recibir más tráfico, los entornos están configurados para expandirse elásticamente mientras sea necesario para responder a la demanda, y encogerse de nuevo cuando el tráfico se regularice.
Al final, fue la implementación de las aplicaciones en ambos entornos lo que terminó tomando más tiempo que el desarrollo de las aplicaciones mismas. Pero a pesar de ello, estos entornos permiten un /deployment/ de aplicaciones más rápido y más resiliente, pues uno ya no tiene que preocuparse por qué servidor utiliza, cómo lo configura, qué paquetes le instala, y demás problemas que acompañan el aprovisionamiento de nueva infraestructura. Para que eso funcione, uno tiene que ajustar la arquitectura de su aplicación para responder a estos patrones efectivamente .
Siguientes pasos
Aunque todo esto suena muy técnico, al final todo esto se trata de facilitar el acceso a información histórica muy importante. Esta es información vinculada a nuestra memoria colectiva y nuestra identidad como Estado-Nación, es nuestra historia política y social, y es una radiografía que explica muchas de las características de la sociedad peruana contemporánea. Es información que debería estar en las manos de más personas, y que debería ser fácil de acceder, complementar y discutir. Con todo tipo de herramientas es posible contribuir y participar a la discusión sobre qué somos y qué queremos ser como sociedad.
Todavía quedan detalles que pulir y terminar en el código, además de documentar los endpoints de la API, pero todo este trabajo está disponible para cualquiera que quiera utilizarlo, revisarlo, o modificarlo. Todo el código está disponible en Github, para el reconocimiento de entidades , conclusiones-api y conclusiones-display . La API está disponible para consultas y el frontend web está ya en línea también . Con suerte, nada se caerá en los próximos días.
Quiero seguir trabajando en esto poco a poco, explorando también otras áreas del Informe Final y explorando cómo pueden transformarse digitalmente. Empecé a hacer estos ejercicios hace unos tres o cuatro años, y en este tiempo es impresionante qué nuevas herramientas han aparecido que hacen todo este trabajo mucho más fácil. Pero también quiero empezar a promoverlo un poco más — no tanto el trabajo, que estoy seguro que alguien con mejor entendimiento de tecnología podría hacerlo mucho mejor, sino más el espíritu de utilizar herramientas digitales para la lectura de problemas históricos, sociales, culturales y políticos. Estas son fronteras que típicamente no se suelen cruzar, pero donde se puede encontrar mucho valor, no tanto para encontrar respuestas sino más para ayudar en la formulación de preguntas que se hacen posibles una vez que tienes disponibles herramientas computacionales. ¿Qué es lo que se hace posible cuando hacemos que una computadora lea las Conclusiones del Informe Final de la CVR?
